- Published on
MSVC's terrible auto-vectoriser for AVX
- Authors

- Name
- icyveins7
The Motivation
I recently decided I wanted to spend some time understanding intrinsics and SIMD at a deeper level.
In developing code for my project ffs, I wanted to make sure that the code was running with at least AVX instructions (because that's my target architecture, and honestly very few computers don't have AVX these days..).
This led me down a path of discovery; first I discovered the amazing-ness that is godbolt.org, then I joined their discord, where I then asked for some help with understanding basic .asm compiler output.
Ultimately though, I needed to know how to write SIMD-tuned functions for complex numbers i.e. std::complex<T>. These were the types that were going into ffs.
Old but Gold Stackoverflows
Some google searching led me to one of the best references for complex-number SIMD multiplication in an answer by Peter Cordes on StackOverflow.
Although it's almost 8 years old at this point, his recommendation is still valid: use -ffast-math and label arrays with __restrict__, and GCC will do a pretty damned good job vectorising with -mavx on.
So with that I placed essentially the same code and compiler arguments - -O3 -ffast-math -mavx - into godbolt again and re-tried it with newer compilers.
I tried first with a simple loop over 4 std::complex<float> values, enough to fill a 256-bit AVX YMM register:
for (int i = 0; i < 4; ++i)
{
z[i] = x[i] * y[i];
}
And indeed, x86-64 GCC 13.2 outputs the following:
vmovups ymm2, YMMWORD PTR [rdi]
vmovups ymm0, YMMWORD PTR [rsi]
vpermilps ymm1, ymm2, 160
vpermilps ymm2, ymm2, 245
vmulps ymm1, ymm1, ymm0
vpermilps ymm0, ymm0, 177
vmulps ymm0, ymm0, ymm2
vaddsubps ymm1, ymm1, ymm0
vmovups YMMWORD PTR [rdx], ymm1
vzeroupper
ret
MSVC.. doesn't auto-vectorise
Using MSVC, the equivalent compiler options would be to use /O2 /fp:fast /arch:AVX. You also have to change __restrict__ to __restrict. This, however, emits the following:
sub rsp, 24
vmovss xmm5, DWORD PTR [rcx]
vmulss xmm1, xmm5, DWORD PTR [rdx]
vmulss xmm2, xmm5, DWORD PTR [rdx+4]
vmovss xmm5, DWORD PTR [rcx+8]
vmovaps XMMWORD PTR [rsp], xmm6
vmovss xmm6, DWORD PTR [rcx+4]
vmulss xmm0, xmm6, DWORD PTR [rdx+4]
vsubss xmm3, xmm1, xmm0
vmulss xmm1, xmm6, DWORD PTR [rdx]
vmovss xmm6, DWORD PTR [rcx+12]
vaddss xmm0, xmm2, xmm1
vmulss xmm1, xmm5, DWORD PTR [rdx+8]
vmulss xmm2, xmm5, DWORD PTR [rdx+12]
vmovss xmm5, DWORD PTR [rcx+16]
vmovss DWORD PTR [r8+4], xmm0
vmulss xmm0, xmm6, DWORD PTR [rdx+12]
vmovss DWORD PTR [r8], xmm3
vsubss xmm3, xmm1, xmm0
vmulss xmm1, xmm6, DWORD PTR [rdx+8]
vmovss xmm6, DWORD PTR [rcx+20]
vaddss xmm0, xmm2, xmm1
vmulss xmm1, xmm5, DWORD PTR [rdx+16]
vmulss xmm2, xmm5, DWORD PTR [rdx+20]
vmovss xmm5, DWORD PTR [rcx+24]
vmovss DWORD PTR [r8+12], xmm0
vmulss xmm0, xmm6, DWORD PTR [rdx+20]
vmovss DWORD PTR [r8+8], xmm3
vsubss xmm3, xmm1, xmm0
vmulss xmm1, xmm6, DWORD PTR [rdx+16]
vmovss xmm6, DWORD PTR [rcx+28]
vaddss xmm0, xmm2, xmm1
vmulss xmm1, xmm5, DWORD PTR [rdx+24]
vmulss xmm2, xmm5, DWORD PTR [rdx+28]
vmovss DWORD PTR [r8+20], xmm0
vmulss xmm0, xmm6, DWORD PTR [rdx+28]
vmovss DWORD PTR [r8+16], xmm3
vsubss xmm3, xmm1, xmm0
vmulss xmm1, xmm6, DWORD PTR [rdx+24]
vmovaps xmm6, XMMWORD PTR [rsp]
vaddss xmm0, xmm2, xmm1
vmovss DWORD PTR [r8+28], xmm0
vmovss DWORD PTR [r8+24], xmm3
add rsp, 24
ret 0
Obviously, not a single YMM register used, and no packed instructions either. You can enable the following MSVC compiler flag, /Qvec-report: 2, to ask it why it didn't vectorise the loop:
<source>(15) : info C5002: loop not vectorized due to reason '1200'
Reason 1200 is apparently 'Loop contains loop-carried data dependencies that prevent vectorization. Different iterations of the loop interfere with each other such that vectorizing the loop would produce wrong answers, and the auto-vectorizer can't prove to itself that there aren't such data dependencies.', which obviously is complete garbage.
I posted all these to the godbolt discord to ask the grandmasters of assembly over there if there was any way around MSVC's issues:
If you'd like to play around with the MSVC implementation, here's the link on godbolt.
Since GCC works, just copy them?
I needed the above to work with MSVC and Windows, so the easiest thing I could think of was to just reverse-translate GCC's output into the appropriate intrinsic calls; I just went to Intel's catalogue and searched them one by one. The model answers are literally given, so why not right?
Word for word translation of the GCC instructions:
__m256 ymm2 = _mm256_loadu_ps(reinterpret_cast<const float*>(x));
__m256 ymm0 = _mm256_loadu_ps(reinterpret_cast<const float*>(y));
__m256 ymm1 = _mm256_permute_ps(ymm2, 160);
ymm2 = _mm256_permute_ps(ymm2, 245);
ymm1 = _mm256_mul_ps(ymm1, ymm0);
ymm0 = _mm256_permute_ps(ymm0, 177);
ymm0 = _mm256_mul_ps(ymm0, ymm2);
ymm1 = _mm256_addsub_ps(ymm1, ymm0);
_mm256_storeu_ps(reinterpret_cast<float*>(z), ymm1);
And their assembly output:
vmovups ymm1, YMMWORD PTR [rdi]
vmovups ymm0, YMMWORD PTR [rsi]
vpermilps ymm3, ymm1, 160
vpermilps ymm2, ymm0, 177
vpermilps ymm1, ymm1, 245
vmulps ymm0, ymm0, ymm3
vmulps ymm1, ymm1, ymm2
vaddsubps ymm0, ymm0, ymm1
vmovups YMMWORD PTR [rdx], ymm0
vzeroupper
ret
If you look closely, the assembly is not 100% identical, but it is functionally identical (just track the registers and you'll see it).
Performance-wise, there is also no difference, as confirmed by the man himself:
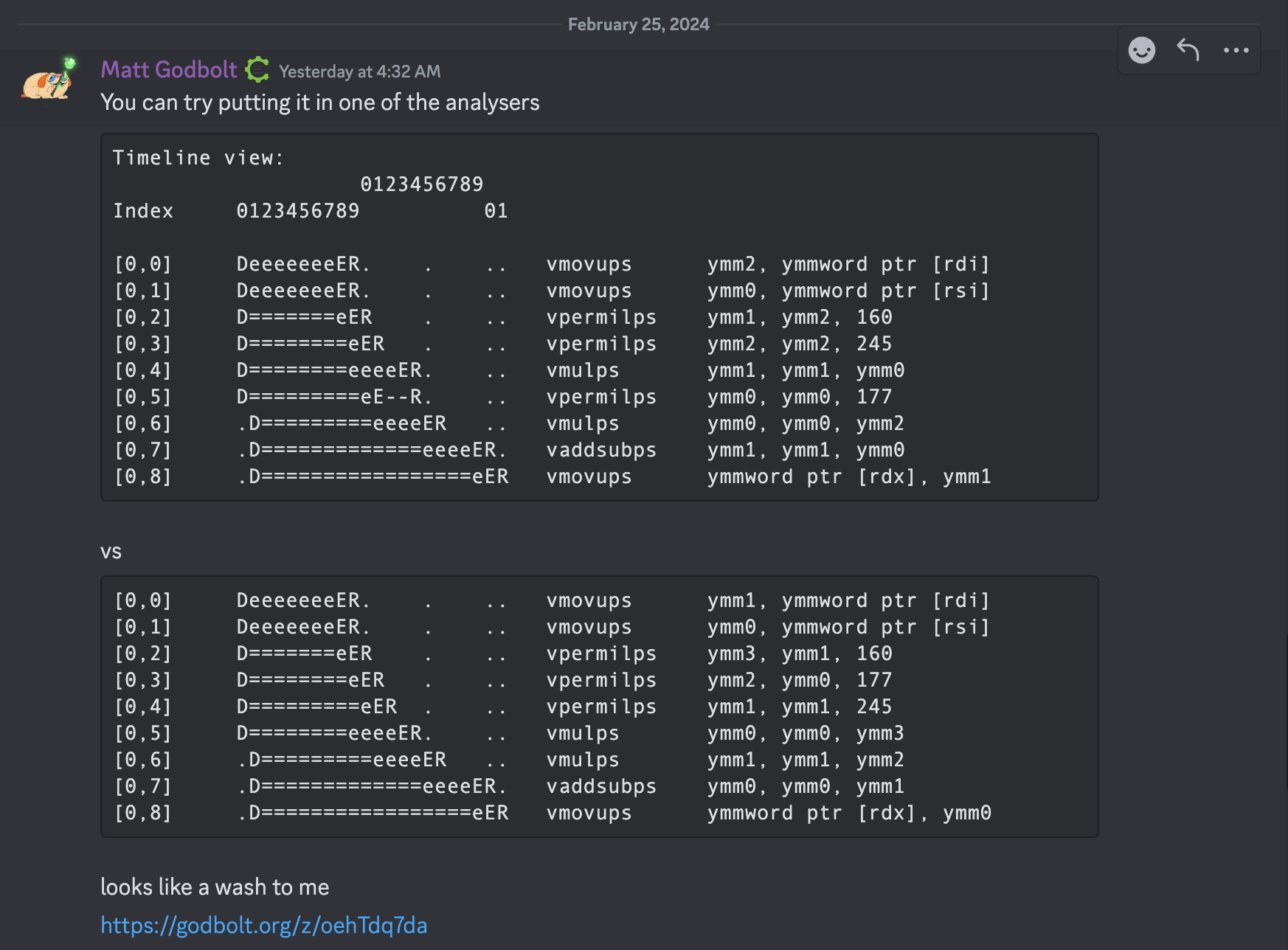
Links to my godbolt are here. Note that if you change it back to MSVC, the original movups instructions will disappear (this seems to be a thing with MSVC assuming/optimizing the arguments away directly into registers).
Some Concluding Remarks
I didn't go into the workings of how the complex number multiplies work, because that's pretty much inside the stackoverflow link.
Also, some might ask why I didn't use a library like Eigen. Yes, I could have, but that would require including a giant library just for one function which is ffs. Also, it was a pretty good learning opportunity.